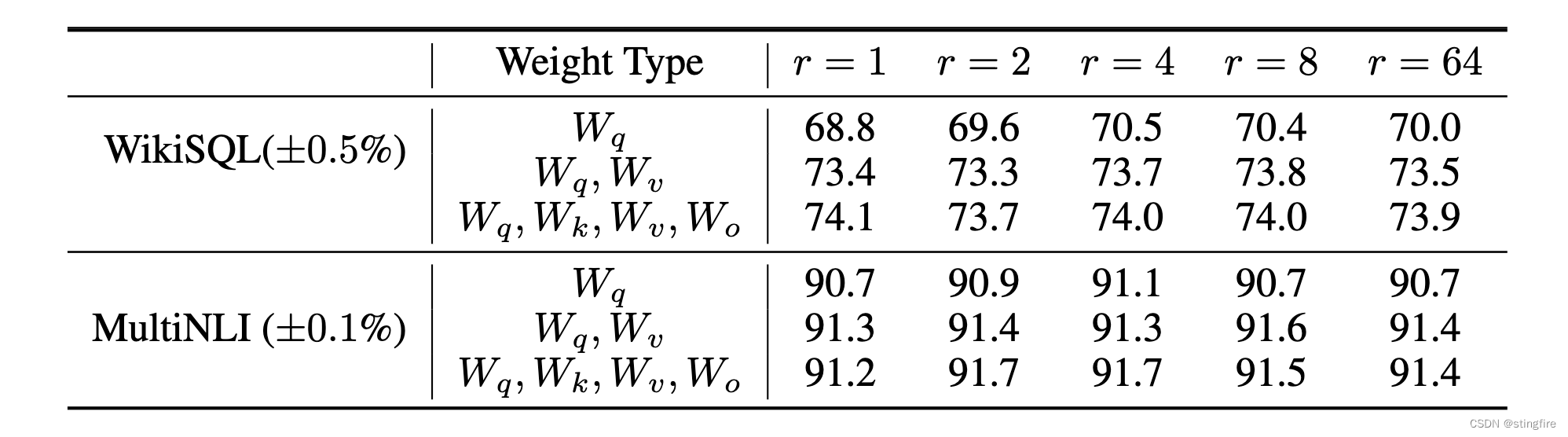
MobileNetV4 - Universal Models for the Mobile Ecosystem
MobileNetV4 - 移动生态系统的通用模型
论文链接:http://arxiv.org/abs/2404.10518
代码链接:https://github.com/tensorflow/models/blob/master/official/vision/modeling/backbones/mobilenet.py (tensorflow)
笔者实现的MobileNetv4 (Pytorch):https://github.com/Reversev/Deeplearning_pytorch/tree/master/CV_net/MobileNetv4
1、摘要
MobileNetV4(MNv4)引入了通用倒置瓶颈(UIB)搜索块,这是一个统一而灵活的结构,融合了倒置瓶颈(IB)、ConvNext、前馈网络(FFN)和一种新颖的额外深度卷积(ExtraDW)变体。除了UIB,还提出了Mobile MQA,这是一个专为移动加速器量身定制的注意力块,提供了显著的39%加速。还介绍了一种经过优化的神经架构搜索(NAS)配方,提高了MNv4搜索的有效性。UIB、Mobile MQA和经过精细调整的NAS配方的整合导致了一套新的MNv4模型,这些模型在移动CPU、DSP、GPU以及专用加速器(如苹果神经引擎和谷歌Pixel EdgeTPU)中大多数情况下都是帕累托最优的,这是其他测试模型中没有的特征。最后,为了进一步提高准确性,引入了一种新颖的蒸馏技术。通过这种技术的增强,MNv4-Hybrid-Large模型在ImageNet-1K准确率达到了87%,在Pixel 8 EdgeTPU上的运行时间仅为3.8ms。

文章目录
- MobileNetV4 - Universal Models for the Mobile Ecosystem
- 1、摘要
- 2、原理
- 额外深度DW IB(ExtraDW)块
- Mobile MQA
- Design of MNv4 Models
- 关键结论
- 设计原则
- Refining NAS for Enhanced Architectures
- Optimization of MNv4 Models
- 3、实验
- ImageNet classification
- COCO Object Detection
- Enhanced distillation recipe
- 4、总结
- 5、附录【可看可不看】
- A、Search space details
- 搜索空间构建
- 我们的优化目标
- B、Benchmarking methodology
- C、Training setup for ImageNet-1k classification
- D、Model details
- E、Larger Pareto curve
- F、Additional Roofline Analysis
2、原理
额外深度DW IB(ExtraDW)块

文中提出了通用倒置瓶颈(UIB)块,这是一种适用于高效网络设计的可调建模块,具有灵活性,能够适应各种优化目标,而不会使搜索复杂度激增。UIB扩展了MobileNetV2中引入的倒置瓶颈(IB)块,后者已成为高效网络的标准构建块[36],并已被广泛应用于高效网络[12,18,32,41]。
在最成功的MobileNet成分——可分深度卷积(DW)和逐点(PW)扩展与投影倒置瓶颈结构的基础上,本文引入了一种新的建模块——通用倒置瓶颈(UIB)块,如图4所示。其结构相当简单。在倒置瓶颈块中引入了两个可选的DW,一个位于扩展层之前,另一个位于扩展和投影层之间。这些DW的存在与否是NAS优化过程的一部分,从而产生新颖的架构。尽管这种修改相当简单,但新建模块很好地统一了一些重要的现有块,包括原始IB块、ConvNext块和ViT中的FFN块。此外,UIB引入了一种新变体:额外深度DW IB(ExtraDW)块。
UIB 实例化:UIB块中的两个可选深度卷积有四种可能的实例化(图4),导致不同的权衡。
- 倒置瓶颈(IB)- 在扩展特征激活上执行空间混合,提供更大的模型容量,但成本增加。
- ConvNext 允许通过在扩展之前执行空间混合以较大的内核大小实现更便宜的空间混合。
- ExtraDW 是本文引入的一种新变体,可实现网络深度和感受野的廉价增加,提供了ConvNext和IB的综合优势。
- FFN是两个 1 × 1 1 \times 1 1×1逐点卷积(PW)的堆叠,中间带有激活和归一化层。PW是最适合加速器的操作之一,但在与其他块一起使用时效果最佳。
作用:在每个网络阶段,UIB提供了灵活性,可以(1)在空间和通道混合之间进行临时权衡。(2)根据需要扩大感受野。(3)最大化计算利用率。
Mobile MQA
Mobile MQA是一种专门针对加速器进行优化的新型注意力块,可提供超过39%的推理加速。
操作强度的重要性: 最近在视觉模型方面的研究主要集中在减少算术操作(MACs)以增强效率。然而,在移动加速器上性能的真正瓶颈通常不是计算,而是内存访问。这是因为加速器提供的计算能力远远超过内存带宽。因此,仅仅最小化MACs可能不会导致更好的性能。相反,我们必须考虑操作强度,即算术操作与内存访问的比率。
MQA在混合模型中高效: MHSA [44]将查询、键和值投影到多个空间中以捕获信息的不同方面。多查询注意力(MQA)[37]通过在所有头部之间共享键和值来简化此过程。虽然多个查询头部是必不可少的,但大型语言模型可以有效地共享一个头部用于键和值而不会牺牲准确性。当批量标记的数量相对较小,而特征维度较高时,一个共享的键和值头部大大减少了内存访问需求,从而显着提高了操作强度。这通常是移动应用的混合视觉模型的情况,其中注意力仅在低分辨率的后期阶段中使用,具有高特征维度,批量大小通常为1。实验证实了MQA在混合模型中的优势。如表1所示,与MHSA相比,MQA在EdgeTPUs和三星S23 GPU上实现了超过39%的加速,而质量损失可以忽略不计(-0.03%)。MQA还将MACs和模型参数减少了超过25%。据作者所知,这是第一个在移动视觉中使用MQA的研究。

整合不对称空间下采样: 受MQA的启发,MQA利用查询、键和数值之间的不对称计算,将空间缩减注意力(SRA)[45]整合到优化的MQA块中,以降低键和数值的分辨率,同时保留高分辨率的查询。这一策略受到了混合模型中空间相邻令牌之间的相关性的观察,归因于早期层中的空间混合卷积滤波器。通过不对称空间下采样,在输入和输出之间保持相同的token数量,保留了注意力的高分辨率,并显著提高了效率。该方法用一个步幅为 2 2 2的 3 × 3 3 \times 3 3×3深度卷积替换了AvgPooling以进行空间缩减,提供了一种成本有效的方式来增加模型容量。
移动MQA:
M
o
b
i
l
e
M
Q
A
(
X
)
=
C
o
n
c
a
t
(
a
t
t
e
n
t
i
o
n
1
,
.
.
.
,
a
t
t
e
n
t
i
o
n
n
)
W
O
w
h
e
r
e
a
t
t
e
n
t
i
o
n
j
=
s
o
f
t
m
a
x
(
(
X
W
Q
j
)
(
S
R
(
X
)
W
K
)
T
d
k
)
(
S
R
(
X
)
W
V
)
(
2
)
Mobile_{MQA}(\bm{X}) = Concat(attention_{1}, ..., attention_{n})\bm{W}^{O} \\ where \ attention_{j} = softmax(\frac{(\bm{XW}^{Q_{j}} )(SR(\bm{X})\bm{W}^{K} )T}{\sqrt{d}_{k}})(SR(\bm{X})\bm{W}^{V}) \ (2)
MobileMQA(X)=Concat(attention1,...,attentionn)WOwhere attentionj=softmax(dk(XWQj)(SR(X)WK)T)(SR(X)WV) (2)
其中SR表示空间缩减,即我们设计中步幅为
2
2
2的DW,或者在不使用空间缩减的情况下表示恒等函数。如表2所示,将不对称空间下采样纳入考虑,可以获得超过20%的效率提升,同时准确率损失最小(-0.06%)。

Design of MNv4 Models
关键结论
-
多路径效率问题:组卷积[52]和类似的多路径设计,尽管FLOP计数较低,但由于内存访问复杂性,可能效率较低。
-
硬件支持至关重要:像Squeeze and Excite (SE) [21]、GELU [16]、LayerNorm[1]等先进模块在DSP上支持不佳,LayerNorm也落后于BatchNorm [23],SE在加速器上速度较慢。
-
简单的力量:传统组件-深度卷积和逐点卷积、ReLU [35]、BatchNorm和简单的注意力(例如,MHSA)- 展现出卓越的效率和硬件兼容性。
设计原则
-
标准组件: 优先考虑广泛支持的元素,以实现无缝部署和硬件效率。
-
灵活的UIB模块: 可搜索的UIB构建模块允许可调整的空间和通道混合、感受野调整以及最大化的计算利用,通过网络架构搜索(NAS)促进了在效率和准确性之间取得平衡。
-
采用直接关注(Employ Straightforward Attention):MobileMQA机制将简单性置于优化性能的首位。
结论:这些原则使得MobileNetV4在所有评估的硬件上基本上是帕累托最优的。
Refining NAS for Enhanced Architectures
为了有效地实例化UIB块,采用了针对性增强的TuNAS [3]。
-
增强搜索策略:通过实施两阶段搜索,缓解了TuNAS对更小滤波器和扩展因子的偏好,这归因于参数共享。该策略解决了UIB深度可分层和其他搜索选项之间参数计数的差异。
-
粗粒度搜索:专注于确定最佳滤波器大小,同时保持固定参数:默认扩展因子为 4 4 4且具有 3 × 3 3 \times 3 3×3深度可分核心的反向瓶颈块。
-
细粒度搜索:在初步搜索结果的基础上,搜索UIB的两个深度可分层的配置(包括它们的存在以及核心大小为 3 × 3 3 \times 3 3×3或 5 × 5 5 \times 5 5×5),同时将扩展因子保持在 4 4 4。

表3展示了通过两阶段搜索实现的增强效率和模型质量,与传统的单阶段搜索相比,在单个TuNAS遍历中探索了统一的搜索空间。通过强化训练使TuNAS更加稳健,TuNAS的成功取决于准确评估架构质量,这对于奖励计算和策略学习至关重要。最初,TuNAS利用ImageNet-1k来训练SuperNet,然而模型在ImageNet上的性能明显受到数据增强、正则化和超参数选择的影响。鉴于TuNAS不断演化的架构样本,寻找一组稳定的超参数是具有挑战性的。

通过离线蒸馏数据集来解决这个问题,消除了额外增强的需求,并减少了对正则化和优化设置的敏感性。JFT蒸馏数据集作为TuNAS训练集,表4中展示了显著的改进。鉴于深度缩放模型在长时间训练中超越了宽度缩放的对应模型[2],作者将TuNAS的训练延长到750个epochs,产生更深、更高质量的模型。
Optimization of MNv4 Models
从NAS优化的UIB块构建了MNv4-Conv模型,根据特定的资源约束进行了定制。更多细节请参见附录A。与其他混合模型一致,我们发现在卷积模型的最后阶段添加注意力是最有效的。在MNv4-Hybrid模型中,将Mobile MQA块与UIB块交错使用,以提高性能。有关详细的模型规格,请参阅附录D
3、实验
ImageNet classification
- 实验设置:为了评估模型架构的性能,遵循标准协议,仅使用ImageNet-
1k[11]训练集进行训练,并在其验证集上测量Top-1准确率。延迟分析涵盖了各种不同的代表性移动硬件,包括ARM Cortex CPU(Pixel6,Samsung S23),Qualcomm Hexagon DSP(Pixel 4),ARM Mali GPU(Pixel 7),Qualcomm Snapdragon(S23 GPU),Apple Neural Engine和Google EdgeTPU。完整的训练设置详见附录C。
在基准测试中,所提模型与先进的高效模型进行比较,包括混合型(MiT-EfficientViT [13],FastViT [42],NextViT [26])和卷积型
(MobileOne [43],ConvNext [32],以及之前的MobileNet版本[19] [36] [18]),基于它们报告的Top-1准确率和延迟评估。值得注意的是,通过现代训练方法增强了MobileNet系列(V1,V2,V3),导致了显著的准确率提升:MobileNet V1提高了3.4%,达到74.0%,V2提高了1.4%,达到73.4%,V3提高了0.3%,达到75.5%。这些增强的MobileNet基线在整篇论文中被用来独立评估架构的进步。
结果如图1所示,并在表5中详细说明,表明MNv4模型在一系列精度目标和移动硬件上大多是帕累托最优的,包括CPU、DSP、GPU以及专用加速器,如苹果神经引擎和谷歌EdgeTPU。

在CPU上,MNv4模型明显优于其他模型,与MobileNetV3相比速度大约快两倍,与其他模型相比在相同精度目标下速度快几倍。在EdgeTPU上,MNv4模型在相同精度水平上比MobileNet V3速度快一倍。具体而言,MNv4-Conv-M模型比MobileOne-S4和FastViT-S12都快50%以上,同时在可比延迟下将Top-1精度提高了1.5%以上,超过了MobileNet V2。在S23 GPU和iPhone13 CoreML(ANE)上,MNv4模型大多处于帕累托前沿。在S23 GPU上,最接近竞争对手MIT-EfficientViT的延迟是MNv4在CoreML上相同精度的两倍以上。FastViT,针对苹果神经引擎进行了优化,在CoreML上排名第二,但在S23 GPU上的延迟是MNv4的5倍以上。像许多混合模型一样,MNv4-hybrid模型与DSP不兼容。尽管如此,MNv4-Conv模型仍然是DSP上性能最佳的,突出了它们在各种硬件平台上的领先兼容性和效率。MNv4-Conv模型提供了出色的硬件兼容性和效率。这一成功突显了UIB块、增强型NAS配方和精心设计的搜索空间的优势。MNv4-Hybrid在CPU和加速器上表现出色,展示了我们Mobile MQA设计的跨平台效率。
普适性对于移动模型至关重要,要求它们在各种硬件平台上表现最佳。评估突显了现有模型在实现这一目标上面临的挑战。MobileNetV3在CPU上表现良好,但在EdgeTPU、DSP和GPU上表现不佳。FastViT在苹果神经引擎上表现良好,但在CPU和GPU上表现不佳。EfficientViT在GPU上表现良好,但在苹果神经引擎上表现不佳。相比之下,MNv4-Conv模型表现出色的兼容性,并在包括CPU、GPU、苹果神经引擎和谷歌EdgeTPU在内的广泛硬件范围上实现了普遍帕累托最优性能。这种多功能性确保了MNv4-Conv模型可以在移动生态系统中无缝部署,无需进行任何特定于平台的调整,为移动模型的普适性设立了新的基准。
COCO Object Detection
- 实验设置: 评估了MNv4骨干在COCO 17 数据集上进行目标检测任务的有效性。将中等大小的MNv4骨干网络与具有相似MAC数量的SOTA高效骨干网络进行比较。对于每个骨干,使用RetinaNet 框架构建目标检测器。将一个256维的FPN解码器附加到P3-P7端点,并使用4个卷积层的256维预测头。与移动检测器一样,我们采用深度可分离卷积来减少FPN解码器和框预测头的计算复杂性。我们在COCO 17 训练集上对所有模型进行600个epoch的训练。所有图像都被调整为384px,并使用随机水平翻转、随机缩放以及Randaug 进行增强。从Randaug中排除了Shear和Rotate增强,因为这些变形会降低小物体检测的AP。训练使用2048的批量大小,Adam和0.00003的L2权重衰减。我们使用余弦学习率调度进行训练,包括24个epoch的预热,并分别调整每个模型的学习率。对于所有基线,我们设置滤波器乘数,使MAC数量大致可比较。在分类实验之后,MobileNet V4骨干使用0.2的随机丢弃率进行训练。所有MobileNet基线均使用官方Tensorflow Model Garden 实现进行训练。

- 结果:实验结果见表6。参数、MAC数量和基准是在384px输入分辨率下计算的整个检测器。中等大小的仅卷积MNv4-Conv-M检测器实现了32.6%的AP,与MobileNet Multi-AVG和MobileNet v2相似。然而,该模型在Pixel 6 CPU上的延迟比MobileNet Multi-AVG低12%,比MobileNet v2低23%。通过在MNv4-Hybrid-M检测器中添加Mobile MQA块,使Pixel 6 CPU延迟增加18%,MNv4-Hybrid-M检测器的AP比MNv4-Conv-M提高了+1.6%,展示了MNv4在混合形式下对目标检测等任务的有效性和效率。
Enhanced distillation recipe
在架构创新的基础上,蒸馏是增强机器学习效率的强大工具。其优势在于移动模型,可能在严格的部署约束条件下提供数倍的效率提升。在强大的Patient Teacher蒸馏基线[4] 的基础上,引入了两种新技术来进一步提升性能。
- 动态数据集混合: 数据增强对蒸馏性能至关重要。尽管先前的方法依赖于固定的增强序列,但作者发现动态混合多个具有不同增强策略的数据集会导致更优秀的蒸馏结果。作者尝试了三个关键的蒸馏数据集:
D 1 D_1 D1 : Inception Crop [39] followed by RandAugment [10] l2m9 applied to 500 ImageNet-1k replicas.
D 2 D_2 D2 : Inception Crop followed by extreme Mixup [51] applied to 1000 ImageNet-1k replicas (mirroring the Patient Teacher approach).
D 1 + D 2 D_1 + D_2 D1+D2: A dynamic mixture of D 1 D_1 D1 and D 2 D_2 D2 during training.

在表7中的结果表明, D 2 D_2 D2在学生准确率(84.1% vs. 83.8%)方面优于 D 1 D_1 D1。然而,动态混合数据集( D 1 + D 2 D_{1} + D_{2} D1+D2)将准确率提升至84.4%(+0.3%)。这一发现表明,数据集混合扩展了增强图像空间,增加了难度和多样性,最终导致学生表现的提升。
-
JFT数据增强:增加训练数据量,通过重新采样JFT-300M [38]数据集至每类130K张图像(总计130M张)来添加领域内、类别平衡的数据。遵循Noisy Student [48]协议,使用在ImageNet-1K上训练的EfficientNet-B0,选择相关性阈值高于0.3的图像。对于数据丰富的类别,选择前130K张图像;对于稀有类别,复制图像以保持平衡。该数据集被复制10倍。由于JFT的复杂性,应用较弱的增强(Inception Crop + RandAugmentl2m5)。这形成了蒸馏数据集 D 3 D_{3} D3。表7显示,仅使用JFT( D 3 D_{3} D3)导致准确率下降2%。然而,将JFT与ImageNet数据结合使用会带来0.6%的改善,展示了额外数据对泛化的价值。

-
蒸馏配方:综合蒸馏配方动态混合数据集 D 1 D_1 D1、 D 2 D_2 D2和 D 3 D_3 D3以获得多样的增强,并利用类别平衡的JFT数据。如表7和表8所示,所提方法相比于之前的SOTA[4]持续取得超过0.8%的top-1准确率改善。为MNv4-Conv-L学生模型训练2000个epoch可获得85.9%的top-1准确率。这展示了所提方法的有效性:学生参数比其教师EfficientNet-L2小15倍,MACs小48倍,但仅准确率下降1.6%。当将蒸馏与在JFT上预训练相结合时,MNv4-Conv-Hybrid达到87.0%的top-1准确率。
4、总结
文中提出了MobileNetV4,引入了新的通用反向瓶颈(Universal Inverted Bottleneck)和Mobile MQA层,并将它们与改进的NAS配方相结合。将这些与一种新颖的、最先进的蒸馏方法相结合,在Pixel 8 Ed-geTPU上实现了87%的ImageNet-1K准确率,延迟为3.8ms,推动了移动计算机视觉的最新技术。此外,作者引入了一个理论框架和分析,以了解什么使模型在异构设备上具有通用性。这是一系列通用且高效的模型,经过调整以在移动生态系统中高效运行。利用多种先进技术,使MobileNetV4在所有移动CPU、GPU、DSP和专用加速器上基本达到帕累托最优,这是其他测试模型中所没有的特征。
5、附录【可看可不看】
A、Search space details
以下是我们为NAS构建搜索空间的方法:
搜索空间构建
- 固定初始层:从第一阶段开始使用一个Conv2D层( 3 × 3 3 \times 3 3×3内核,步长 2 2 2)进行快速分辨率降低,然后在第二阶段使用NAS优化的FusedIB块(步长2)来在效率和准确性之间取得平衡。
- NAS驱动优化: NAS过程精确确定了在剩余四个阶段中理想的UIB块数量和参数实例化,确保了性能的最佳结构。
- 固定头层: 使用与 MobileNet V3 相同的头层配置。观察到UIB块内的逐点卷积在更高分辨率下往往表现出较低的操作强度,我们优先考虑在初始层中具有更高计算密度的操作,以平衡效率和准确性。
我们的优化目标
- MNv4-Conv-S: 双重目标—285M次乘加运算(Pixel 6 EdgeTPU,224像素输入)。
- MNv4-Conv-M: 0.6毫秒延迟(Pixel 6 EdgeTPU,256像素输入)。
- MNv4-Conv-L: 具有384像素输入的双延迟目标,分别为2.3毫秒(Pixel 6 EdgeTPU)和2.0毫秒(Pixel 7 EdgeTPU)。
需要注意的是,通过将搜索空间限制在在各种设备上具有良好相关成本模型的组件上,作者发现**EdgeTPU延迟优化直接产生了通用高效模型*。
B、Benchmarking methodology
在各种移动平台上采用了一致的基准测试策略,但对于苹果神经引擎有一个例外。为了提高效率,模型被转换为TensorFlow Lite格式,并对移动CPU、Hexagon和EdgeTPUs进行INT8量化,而移动GPU则使用FP16。对每个模型运行约1000次,并取这些运行的平均延迟。然后对每个模型重复该过程5次,并报告平均值的中位数。为了优化性能,文中将CPU亲和性设置为最快的核心,并在CPU评估中使用XNNPACK后端。相比之下,对于苹果神经引擎的基准测试(在iPhone 13上进行,使用iOS16.6.1、CoreMLTools 7.1和Xcode 15.0.1进行分析),PyTorch模型被转换为CoreML的MLProgram格式,精度为Float16,使用float16 MultiArray输入以最小化输入复制。

C、Training setup for ImageNet-1k classification
为了提升模型性能,文中的训练方案融合了广泛采用的数据增强技术和正则化方法。对于数据增强,使用Inception Crop(Inception裁剪)[39],水平翻转,RandAugment(RandAugment)[9],Mixup(Mixup)[51],以及CutMix(CutMix)[50]。对于正则化,应用L2归一化和随机深度剪枝(stochastic depth drop)[22]。数据增强和正则化的强度根据模型大小进行调整,详见表9。
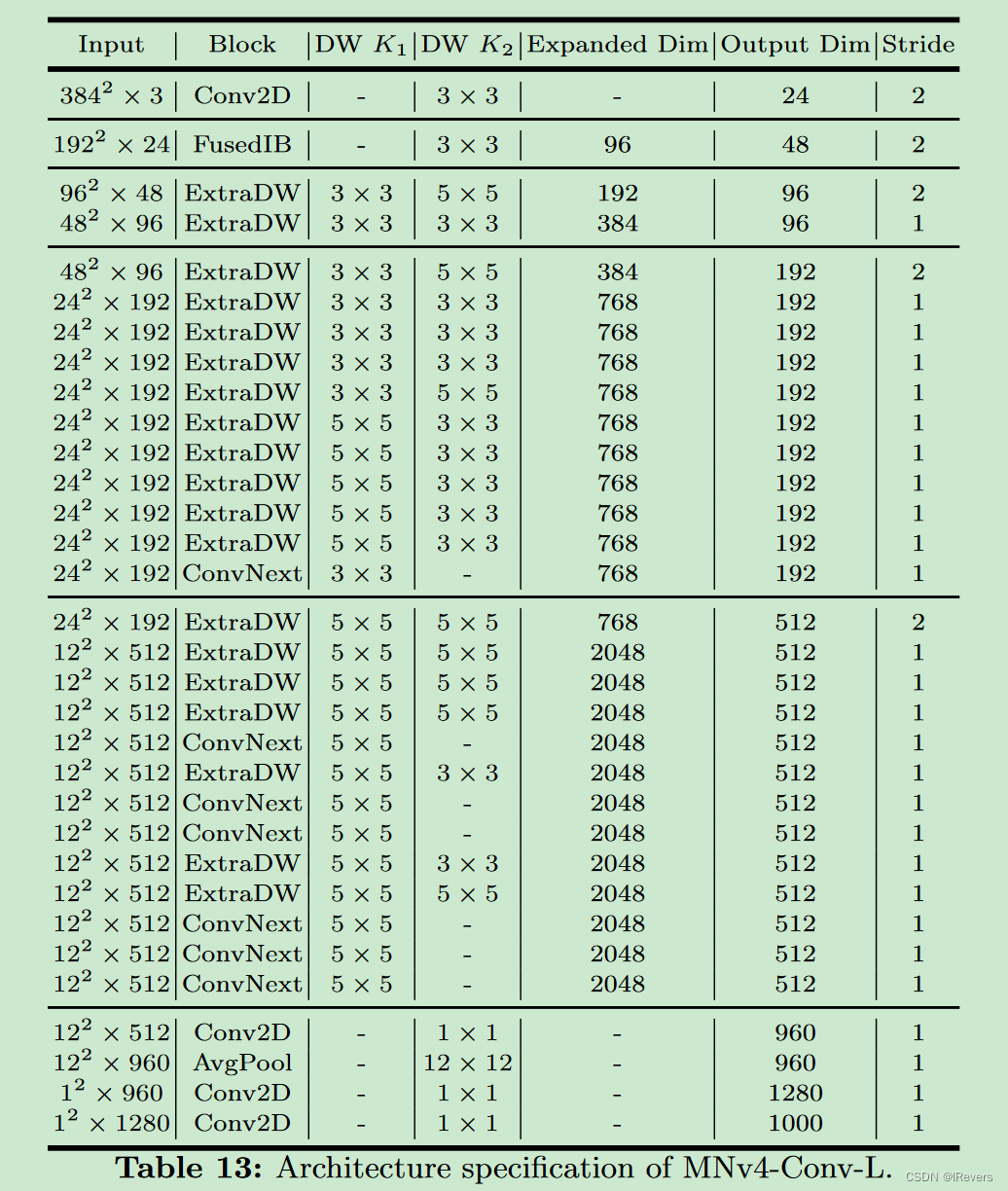
D、Model details
MNv4模型的架构细节从表10到表14中描述。以下是经过TuNAS优化的MNv4-Conv模型的细节。Tu-NAS优化的宏架构战略性地结合了四个UIB实例化:Extra DW、ConvNext、IB和FFN。这种组合展示了UIB的灵活性以及在网络不同阶段使用不同实例化块的重要性。具体来说,在每个可搜索阶段的开始,空间分辨率显著下降时,ExtraDW成为首选选择。ExtraDW中双深度层的设计有助于扩大感受野,增强空间混合,并有效缓解分辨率损失。类似地,出于类似原因,ExtraDW经常在MNv4-Conv模型的早期阶段被选择。对于最终层,前面的层已经进行了大量的空间混合,因此选择了FFN和ConvNext,因为通道混合提供了更大的增益。




E、Larger Pareto curve

F、Additional Roofline Analysis
这将分析从图3扩展到包括MobileNetV4-Conv-Small(图7)、MobileNetV4-Conv-Medium(图8)和MobileNetV4-Conv-Large(图9)。这些图表还将从每个数量级的角度展示从 0.0 MACs/byte 岭点(仅MACs,内存带宽无限)到500.0 MACs/byte 岭点(类似加速器,受限于内存带宽)的扫描。还包括了测量延迟、经验拟合的roofline 模型和 MACs 计数之间的相关性分析(表15 和图6)。


这些是表15中考虑的模型。屋顶线模型成功地捕捉了每个硬件目标上每个模型系列相对于帕累托前沿的相对顺序,但是每个目标上还有一些屋顶线模型无法捕捉的额外细微差别。



之前没有卷积MobileNets比MobileNetV4-Conv-Large更大,因此,这与ConvNext-Small和MobileOne-S4进行对比。ConvNext-Small被包括在内,因为它在S23GPU上的延迟与MobileNetV4-Conv-Large相似。MobileOne-S4被包括在内,因为它在Pixel8 EdgeTPU上的延迟与MobileNetV4-Conv-Large相似。